 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps About Us
About Us Contact Us
Contact Us Careers
Careers
 Reading Time: 5 minutes
Reading Time: 5 minutesIn recent years, we witnessed the rise of Machine Learning and AI, with the global market growing from $1.58 billion in 2017 to over $7 billion in 2020.
The public cloud is a natural fit for ML and AI and there are many good reasons for moving some, or all of your machine learning projects to the cloud. The pay-per-use model is ideal for bursty machine learning workloads, e.g. tuning hyperparameters or training a large BERT-like model. You can also leverage the speed and power of GPUs for training without having to make massive investments in hardware that you might only need for a short period.
While the cloud already offers great flexibility and makes large projects financially viable, it still can be quite costly. Buying Reserved Instances and Savings Plans might not be the way to go for short-term projects. On the other hand, Spot Instances, which offer up to 90% discounts off of On-Demand pricing, can be ideal, especially when you don’t have to worry about the dark side of Spot Instances, i.e. unplanned interruptions.
In this blog post we will show you exactly how you can enjoy rock-bottom, cloud compute pricing with high availability, for all your ML projects.
P3.2xlarge vs. G3.4xlarge for Your CIFAR Dataset
For the sake of this demonstration, we will explore a relatively simple use case, and then compare how much we were able to save by leveraging Spot Instances in comparison to the “On Demand” pricing model.
We will train a state-of-the-art model over the CIFAR dataset, using different hyperparameters, e.g., batch size and learning rate. We will replicate the same procedure for two Accelerated Computing EC2 instances, and leverage their GPU for our model. We will compare their costs within two pricing AWS EC2 models, On-Demand and Spot.
More specifically, we chose a p3.2xlarge instance which consists of one Nvidia Tesla V100 GPU, and the other instance type, a more modest g3.4xlarge, giving us Nvidia Tesla M60 GPU. For each instance, we trained our model 4 times with different hyperparameters. Ultimately we trained our model over the CIFAR dataset 8 times, changing 3 things: batch-size, learning-rate and instance types.
Note: we trained our model for 200 epochs, although in many cases our model converged sooner than that.
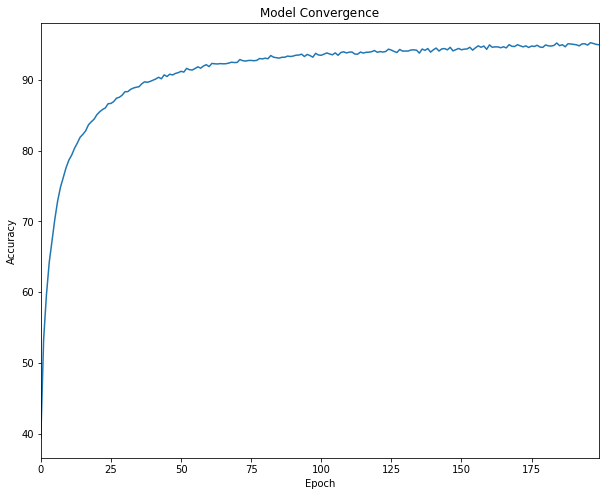
Running ML Projects Affordably in the Cloud
For our ML use case we used Spotinst Managed Instance to run on a Spot Instance while staying resilient to sudden instance interruptions. Let’s examine how much this saves us.
We can take the run time of each training session with its respective hyperparameters and see how much it cost us to train our model.
In our relatively simple scenario, we can see that such processes are time consuming and as a result of the public cloud pricing model, costly as well. But worry not, as mentioned above, leveraging public cloud excess capacity such as EC2 Spot Instances actually saved us a lot of money.
Using the Spotinst API, we can grab stats about how much we paid to run our EC2 Instances, as you can see in the screenshots below of the Spotinst Dashboard, we were able to save a substantial amount of money by using Spot Instances instead of the potential On-Demand costs.


We were able to derive the actual cost for each time we trained our model by recording the training run time from start to finish and multiplying said run time with the respective amount our specific chosen instance types, cost per hour.
With this, we will demonstrate the price difference between all instance type for the same model training, only adjusting Batch Size and Learning Rate:
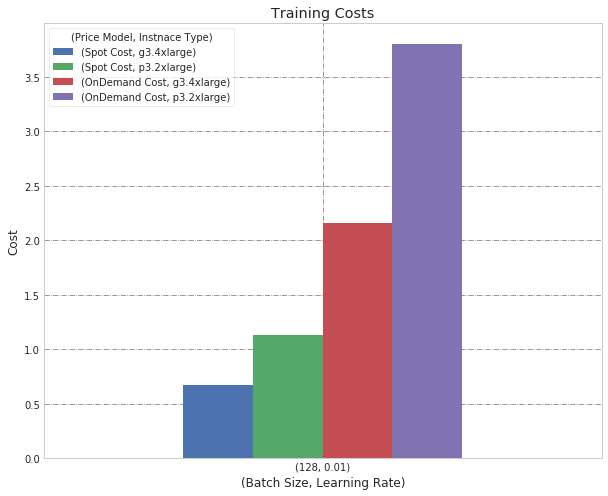
Starting with batch size of 128, we show two graphs with different learning rates:
Batch Size 128, Learning Rate 0.01
Batch Size 128, Learning Rate 0.1
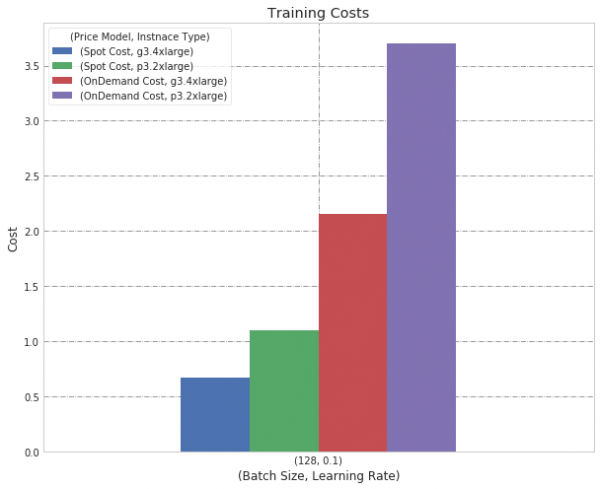
We observed a big difference between Price Models, as the On-Demand Price Model is significantly more costly. Importantly, we also see that the g3 instance is more cost-efficient than the p3.
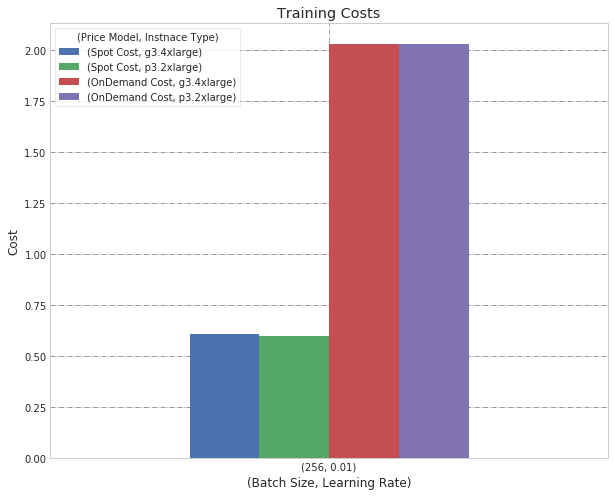
Next, we change the batch size to 256:
Batch Size 256, Learning Rate 0.01
Batch Size 256, Learning Rate 0.1
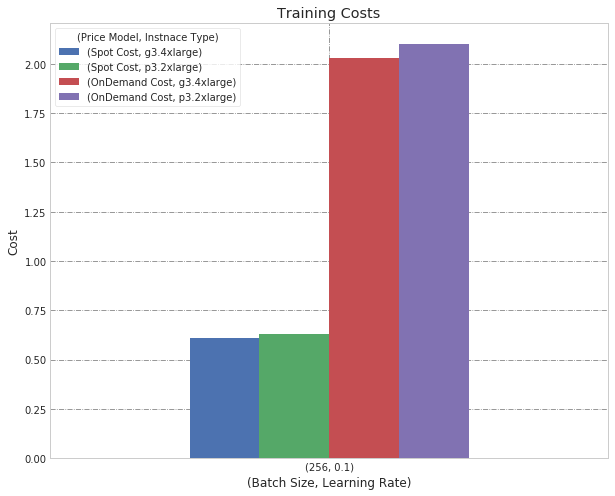
After we adjusted the Batch Size from 128 to 256, we see that accuracy drops (with both instance types), but our training concluded faster with the p3.
As the model training was significantly faster with the p3, it also reduced the cost to the point where there was hardly any difference in cost between the two instance types. Therefore, for a larger batch size, we suggest the p3 instance as it is much faster and the price difference compared to g3 is negligible.
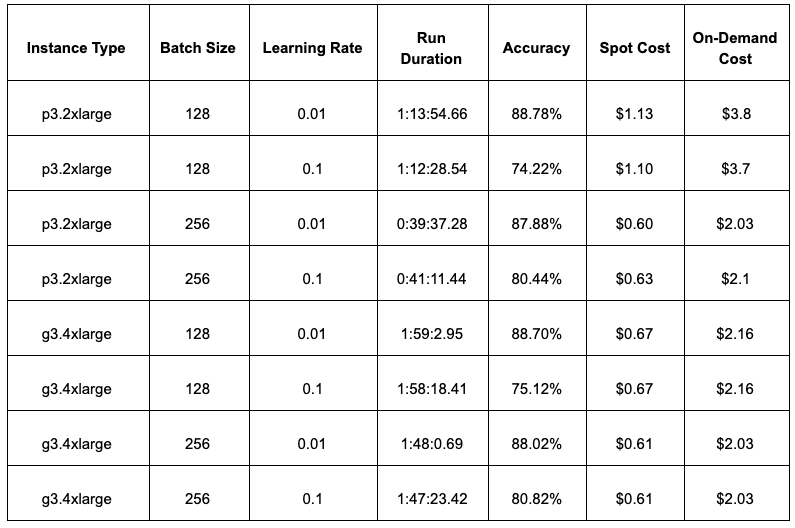
Here is a summary table of all the results:
Machine Learning in the Cloud Recommendations
To sum up the key takeaways, in many cases the public cloud is a natural fit for machine learning use cases, by offering variety and flexibility. In terms of choosing the right AWS pricing model, you can reliably run on Spot Instances to achieve ~70% cost savings in comparison to On-Demand pricing.
Aside from EC2 pricing models, the choice of the specific instance is also important with two things to consider:
- The total amount of time expected to use the cloud hardware
- The hardware price per time used
In our test this played out as follows:
- For smaller batches, it was more cost effective to use the g3.4xlarge instance type (Nvidia Tesla M60).
- But for a larger batch size, the price premium we paid for the p3.2xlarge (Nvidia Tesla V100) was worth it, as the faster training time almost completely offset the higher cost.
To get started with your machine learning project on Spot Instances with high availability, such as we used above, see our previous blog post that details step-by-step how to do so.
Of course, if you have any questions about running your ML training on Spot Instance, we would love to hear from you.