 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps About Us
About Us Contact Us
Contact Us Careers
Careers
 Reading Time: 4 minutes
Reading Time: 4 minutesAs more and more enterprises containerize their applications, they want to run their mission critical workloads using Kubernetes. There is a misconception in the industry that containerized environments are mainly useful for running stateless workloads. However as Kubernetes matures, the community is working hard to support stateful workloads to meet the needs of enterprise customers. In the 2018 CNCF survey, one-third of respondents pointed out storage as one of their challenges but the number has come down dramatically from the previous surveys, and there has been excellent progress in supporting Stateful workloads ever since. In this blog post, we will talk about running stateful workloads on Kubernetes and how Spot by NetApp Ocean supports such workloads while also leveraging Spot Instances.
Stateful Workloads on Kubernetes
Kubernetes has been supporting stateful workloads directly since version 1.9 when StatefulSets was made generally available. Kubernetes users have been asking for support for persistent volumes for a while and it is now mature enough to support stateful applications like databases, big data and AI workloads. Kubernetes support for stateful workloads comes in the form of StatefulSets.
Requirements
For Kubernetes to support stateful workloads, it has to meet the following requirements:
- Support for multiple persistent storage volumes (both on Cloud and On-Premises).
- These persistent volumes should be available across Pod restarts or new Pod after termination. This means that the storage and network identities survive the restarts.
The support for the latter is more important. The Kubernetes Pods are ephemeral but most stateful applications need persistent storage whose storage and network identities survive Pod reboots. For example, the IP address should be preserved when pods are restarted and this process should be managed seamlessly without any user intervention. With the ever growing list of cloud providers and other storage offerings, Kubernetes typically supports this out of the box.
Check out our guide for running Elasticsearch on Kubernetes
Stateful Applications with Database on Kubernetes
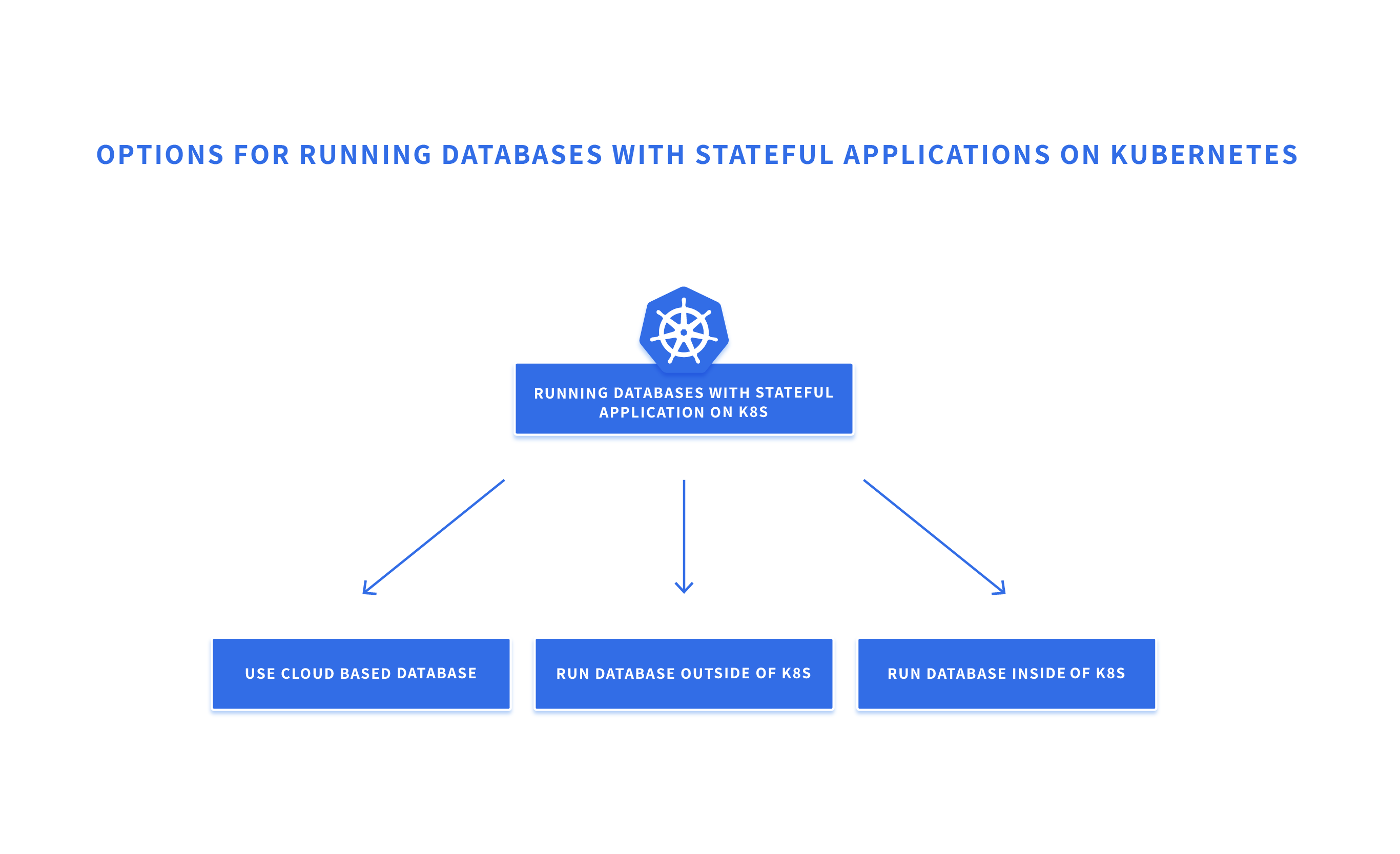
There are three main approaches to running databases needed for stateful applications running on Kubernetes:
Using Cloud Services
In this approach, a Database as a Service offered by the cloud provider or a third party vendor is used. Users need not worry about managing the database and they just focus on running the apps on Kubernetes without worrying about the state. Even though it reduces some of the operational overhead associated with running the database, it adds some latency and there is a risk of losing control over the data to a third party. Cost also is typically higher when using managed services such as this.
Running Database Outside of Kubernetes
You could run the database outside of the Kubernetes environment with the same cloud provider. You could use the cloud provider’s elastic compute service and run your database using virtual machines. Then it is your responsibility to manage volumes, HA, scale, etc.. This adds significant operational overhead. Alternatively, you could run the database on top of Spot by NetApp’s Managed Instance which supports Stateful Applications. Since our Managed Instance solution takes advantage of spot instances, you could realize considerable cost savings.
Running Database Inside Kubernetes
There are many reasons, including performance needs, to run the database inside the Kubernetes environment. This is where the support for stateful applications in Kubernetes becomes important. Stateful applications in Kubernetes can be deployed using StatefulSets.
StatefulSets is the Kubernetes API object which allows users to run stateful workloads by ensuring that the same network ID and persistent disks are available after Pod restarts. This works even if the Pods are brought up in other nodes. At this point only remote volumes are supported and support for local disk is in beta. StatefulSets offer support for various Storage Classes including the persistent disks offered by various cloud providers.
StatefulSets can be leveraged while running the Kubernetes environments on top of Ocean.
Ocean supports stateful applications on top of Spot Instances to help significantly optimize cloud cost while simplifying infrastructure management. Ocean is aware of any persistent volumes attached to your pods and upon any Spot Instance termination, will verify that the cluster will have sufficient resources in order for the pod to be rescheduled and attached to the persistent volume.
Considerations for Stateful Applications on Kubernetes
Kubernetes based platforms help orchestrate containers at scale, making them attractive for the enterprise cloud-native needs. Kubernetes platforms help DevOps with greater agility thereby, empowering developers to build applications at the speed of business. As Kubernetes also supports stateful applications, it is important to consider the following while evaluating Kubernetes platforms for stateful workloads:
- Does the platform make it easy to run stateless and stateful workloads?
- Does the platform provide persistent volumes with IP address surviving Pod and node reboots?
- Does the platform make it easy to ensure HA and DR for stateful applications?
- Does the platform meet the SLA needs?
- Does the platform work across multiple cloud providers
In summary, with Kubernetes becoming the de facto standard to run containerized workloads, it makes sense to carefully evaluate your requirements so you can use Kubernetes for as many stateless and stateful workloads as possible.